Insurance Data Solutions
Registered Address:
Dalton House,
9 Dalton Square,
Lancaster,
LA1 1WD
Contact Information
Telephone:
44 (0)1376 437777
Email:
enquiries@
insurancedatasolutions.co.uk
To prepare and execute a successful insurance data migration project there needs to be a well-defined methodology which needs to be well understood and supported by all parties involved. Differences between the business processes, user interface layers and data structures in the source and target systems increases complexity.
Failure to pay attention to business rules and data quality can impede efficiency of processes and lead to loss of business. Maintaining the integrity of the data is often overlooked, resulting in data inconsistencies and multiple versions of the same contract.
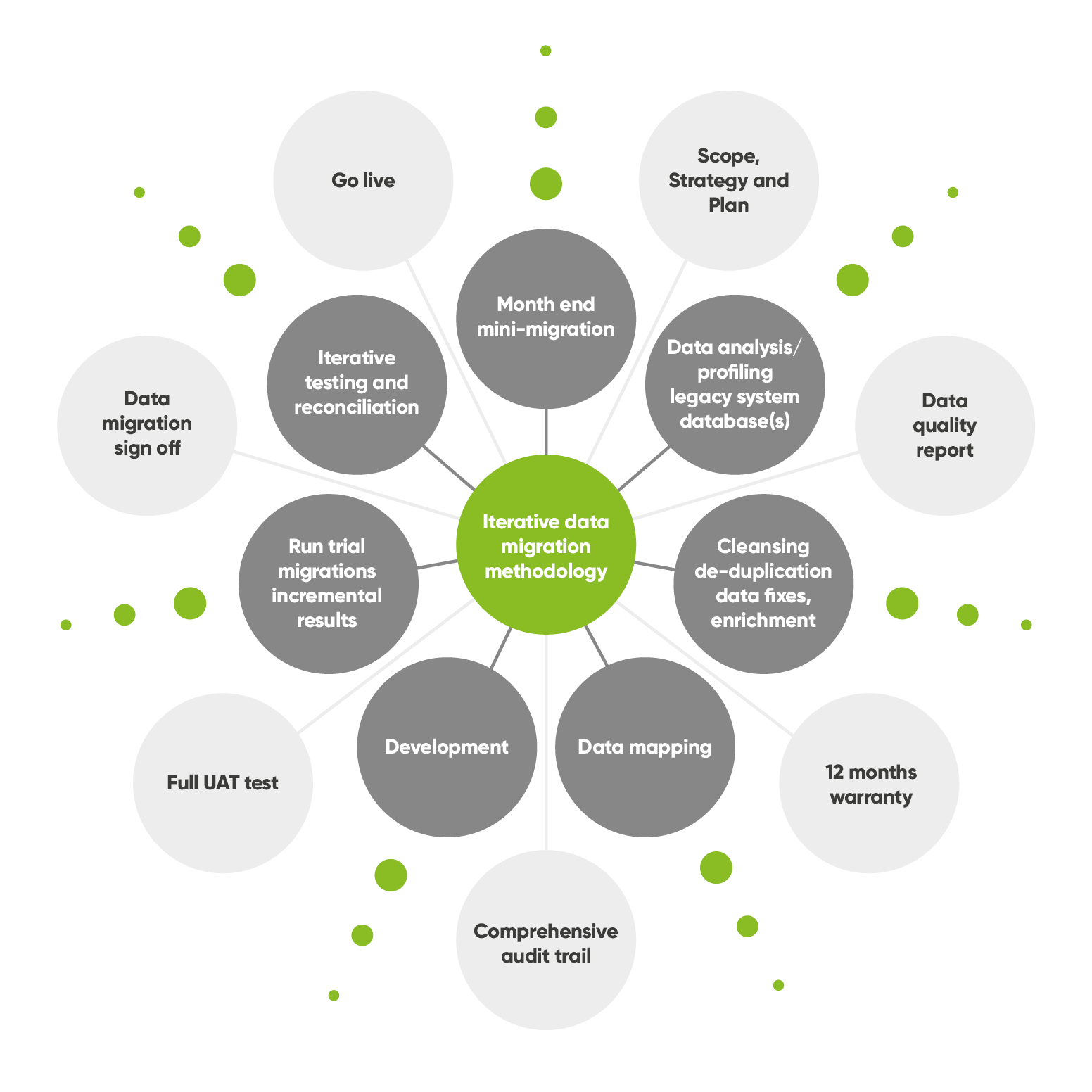
Our Insurance data migration methodology diagram illustrates our incremental and iterative approach for a comprehensive end to end data migration project.
For each area of data (i.e. clients, policies, risks, claims, accounts or documents) the inner gray circles of the diagram are effectively repeatable stages. This ensures issues are identified early during a series of releases i.e. mini migrations thus providing opportunities for feedback and if necessary, re-working.
Therefore, insuring the final release meets the business users’ requirements with no surprises on the live migration.
Engagement with the client right at the start of the project is vital in-order to gather information on the legacy and target systems involved and the type, quantity, quality of the data being migrated and the business rules that apply.
The results of an initial data analysis are also invaluable during the planning stage when deciding what to migrate and the approach to be taken.
Also factors like budget, on-site or off-site delivery, resources available and project deadlines all need to be considered to determine the best strategy and delivery method. These are the kind of questions that will need answering to establish the resources required, time-frame for delivery, the best migration solution and to establish the costs to do the migration.
Data analysis and cleansing are on-going and iterative activities. Any new items of data that appear during the iterative phases must comply and be up to standard for the new system to run properly.
Data Analysis
Our data migration team will carry out an independent unbiased assessment of your data which can include client information, high-level policy information, risk information, documents, accounts, claims, diaries and notes. All data formats including relational databases, spreadsheets, text files, scanned images and paper documents can be analysed and migrated to fit into the target system.
Our Insurance Data Migration Framework includes a data analysis tool which efficiently analyses and reports on what can be mapped from source to target system. A detailed Specification Report will then be developed which will outline the logic we use for the migration summarising mapping requirements. Our data migration team will then use this to consult with the business and agree on mapping rules.
The Data Analysis stage includes a data quality assessment which checks the accuracy and completeness of the data i.e. where there are data quality issues, gaps and redundant questions in the data, duplication issues and validation problems etc. This process will highlight data that does not meet the criteria set out in the new target system and what needs to be cleansed and modified prior to a migration.
A Data Quality Assessment is included in the initial data analysis done at the Scoping and Requirement gathering stage and then also once the project starts during the Data Analysis stages whenever we receive new data (i.e. usually month end).
The Insurance Data Migration Data Quality Report will include information on the age / value and quality of your data, details of each issue what data fixes and data enrichment is required to ensure your data meets the standards set by the business and performs correctly in the new system.
Our IDM team will regularly consult the business on any issues they find once they have been fully investigated. And, give recommendations as to how best rectify them i.e. sometimes it can only be achieved through an automated process or in other instances it may be better for business users to rectify the data manually.
Every insurance data migration brings up different data quality issues and mapping requirements. Our insurance data migration team have detailed knowledge of insurance data and our methodology and processes ensure issues are easily found and rectified in consultation with the business before the go-live migration. When we update your data, we will always include what, when and how it was done in a Comprehensive Audit Trail.
You don't want to encumber a new system's performance with useless and incorrect data. So a data migration can offer an ideal opportunity to have a good cleanse and tidy-up. Data cleansing is done off the back of consultation with the business following data analysis. During extract, transform and load (ETL) stages data correction and cleansing usually takes place alongside the mapping stages and therefore the final Data Quality and Mapping Requirements are drawn together into one report.
Migrating data from one system to another almost always requires a large amount of data manipulation. There will always be gaps in the data and parts of the data which require transformation. All the factors which can render the data unfit for migration in its present state will need to be cleansed. However, our expertise and Insurance Data Migration Framework will ensure that all critical data is up to standard for the new system to run properly.
Detailed extraction scripts based on your criteria will filter out information and we use our expertise to improve the quality of your data through data fixes and enrichment techniques i.e. using address updating tools.
Data quality management is an ongoing activity and any new items of data that appear during the iterative migration phases must comply with your data standards and business rules. Within our Insurance Data Migration Framework tool, we update our filters to ensure the required level of data quality.
Our IDM team produce documentation on the details of what business and technical rules will be used for the migration. A document will be produced which will contain all of the agreed business rules which will be used to determine the number of years of policies to migrate, which risks to migrate, which systems to take the information from.
This above document will be supplemented with excel files containing comprehensive technical details of the migration. This ensures that no area of the project is overlooked and that you know exactly what you will be getting when the project goes live.
All changes to the specifications will be documented so that there is a clear auditable record of the whole project. At an agreed stage in the project, the specifications will be signed off by the IDM team and your project lead.
The specification document will be agreed with you before and during to the development phase. This document will be written in such a way that any user of the system will be able to understand the migration. This document will also give you a quick guide on how the migration will work. This will ensure that if there are any changes to your project team everyone will be fully up to speed on the process.
We write the technical specifications using our Insurance Data Migration Framework tool and extract these into an Excel document.
This document will contain specific information on the transformation of your data. It will contain the following:
• Table-by-table logic, for example, for commercial motor insurance if the claims history may be stored per policy on your current system but stored per driver on your new system. We will detail what we have agreed with you on how this information will be taken across.
• Field-by-field logic, for example, you may have a text field in your source system which contains a few pieces of information about the risk. Whereas, your new system has this information split out. We will explain where the text field will go to in the new system.
• Any transformations to the data, for example, if your source system contains a text field for the title and this is a drop-down field in the new system then we will use mapping to ensure each source value goes to the correct drop-down option. Details of this can be seen in the value mapping section below.
Our technical specifications usually contain one excel spreadsheet per each of your new system’s screens. We then list out all the new fields and have an empty technical specification ready to be completed. Our team will then use the results of the data analysis to determine which of the fields from the source system should go to each of the target system’s fields.
To ensure that all the required source system’s fields are migrated across we also keep a document which lists out all the source system’s screens and fields. We then tick off any field that is completely migrated.
Value mapping is the process of taking a specific value in one of your source systems fields and mapping it to a specific option in your new system. Migrating large volumes of insurance data correctly requires a good understanding of the complex and densely interconnected manual and system processes involved.
A great deal of data stored in legacy applications is bound up with inter-dependencies and the mapping and merging of this data requires great care. It is critical to perform careful mapping to ensure continued communication with other systems (i.e. EDI, MID, ELTO) etc.
Our insurance data migration teams’ expertise, Insurance Data Migration Framework tools and testing techniques in data mapping ensure the data fits, makes sense and works correctly in the target system.
As part of the development stage, our Insurance Data Migration Framework Tool automatically generates scripts for much of the development phase by reducing the level of hand coding required. Built specifically for migrating insurance data, it speeds up our processes significantly. This development stage is when the extraction of data from the source, transformation and loading to target tables takes place and where all the data manipulations are carried out in accordance with business and mapping rules.
Our insurance data migration team have experience in using ETL (Extract-Transform-Load) tools such as SSIS, and in writing custom modules using technologies such as SQL scripting or CLR’s in C# and Python, as well as traditional code languages such as Dibol and Cobol.
Each migration has its own demands and our insurance data migration team have a wide range of methods available. Quite often a migration may be made up of both ETL tools and custom modules. Whichever method is chosen the conversion modules will include the business, mapping and cleansing rules that were defined in the earlier stages.
Naturally, users of your legacy system may be resistant to change. During the development stage, our insurance data migration team will use a phased approach showing your users incremental results through early data conversions which help in setting their minds at rest.
For example, once the development for client details is complete our team will migrate and showcase to business users the data successfully working in the target system. This can be done through workshops and/or on a one to one basis with key stakeholders. These early conversions are then repeated for each area policies, risk, claims, accounts, documents etc.
This phased approach helps fine-tune each migration and delivers more accurate results in a quicker time-frame due to the data being seen early. Considering one area at a time reduces risk. Delivering value early provides opportunities for feedback and if necessary reworking so that the final release meets the businesses exact requirements.
Through-out a migration project, our insurance data migration team will refresh the legacy data on a monthly basis adding any new data you send us, carrying out mini-migrations of all the data. This approach ensures that any new values or trends in the legacy data can be identified and any new issues can be resolved early. It also means that come the live migration you have comfort in knowing that numerous end to end migrations have been completed successfully and there should be no surprises.
Having been through numerous go-lives, our IDM team have extensive knowledge in good go live procedures for migrations. We have experience in resolving any go-live specific issues to ensure that there is no delay on the system getting up and running.
Migrations tend to happen when the business is closed either overnight or for some larger projects over a weekend. The new system will then be up and running the next business day ready for users to resume their usual processes. As part of the build-up towards the go-live, IDM will get fresh copies of the source data roughly a week before go-live. This allows the team to check for any new data quality issues or other changes since the last cut of data. This means that on the go live there will only be one week of data for the team to check.
Go-lives generally follow a standard procedure which we tweak for each of our customers’ needs. The IDM team create a plan for each customer with an exact minute-by-minute timeline. This ensures that there are no surprises during the go live and that the whole process runs as smoothly as possible. Each of the releases that the IDM team do as part of the iterative process allows timings to be confirmed multiple times during the project, this makes them as accurate as possible. The main steps of a standard go live are:
1. IDM receives the latest data
2. IDM checks this data
3. IDM runs the migration
4. IDM reconciles the migration
5. IDM sends the data to the software provider
6. The software provider releases the data into the new system
7. Client tests the integrity of the migration
8. IDM team send final reports
9. Go live!
Testing and checking are often not given enough time and attention in mainstream projects and data migration projects are no different. To deliver a successful migration, testing requires an iterative approach throughout the migration process which is critical to reducing risk.
Using a test environment which contains a read-only copy of the source database and a clean copy of the target database. Our insurance data migration (IDM) team will test using a number of methods including, focus testing using SQL and comparison of source and target system with migrated data.
Quite often it is the data that you can’t see on the screen such as flags and counts that can causes problems in migrations. Comparison testing may not pick up certain data for instance in policies that have specific details that perhaps do not affect a large number.
Our IDM teams experience and focus testing techniques ensure rare attributes to policies are identified and migrated completely. For instance, looking specifically at car insurance policies where additional drivers have convictions and checking these values are coming through in the target system correctly.
Our IDM team will also do a certain degree of User Acceptance Testing (UAT) system testing themselves. For example, completing tests on migrated policies ensuring that they can endeavour the end to end policy process. Testing to ensure migrated policies can be renewed, adjusted, cancelled and re-quoted.
Out IDM team carry out tests after every release of the migration to ensure:
The data migration process performs relatively fast and without any major bottleneck.
In order, to reconcile the migrated data, we have a detailed suite of reconciliation scripts, which will extract total counts and summations of critical data for each of the business areas from the legacy, interim and target databases. Any discrepancies will be reported and must be understood and within an agreed tolerance limit. Typically reported in a spreadsheet form these figures are broken down by business area to independently validate the end to end migration process. This ensures the mitigation of any differences and secures confidence in the migration.
As a simple example, reconciliation can identify the number open and closed claims in the source system with the number of open and closed claims in the target system ensuring we are not missing off any critical data. The documented results of the Reconciliation will be an element of our Comprehensive Audit Trail.
User testing is very important it should not be compromised. As your company migrates from one platform or operating system to another, you need assurance that your data has been kept intact throughout the migration. Therefore, the results of each migration release need to be systematically tested.
User Acceptance Tests (UAT) carried out by the business users will ensure the target system performs as expected once the migration data has been loaded. UAT by the business is critical in ensuring the client gets the best end product possible as even though our Insurance Data Migration Framework has many robust testing techniques in place, it is the client who knows their data the best!
Once all the analysis, development and testing stages are complete our Insurance Data Migration (IDM) team will hand over all sign off documentation which details the data migration at both a business and technical level. This documentation will include;
This document is created during the data and system analysis stages and is used as a technical reference guide which explains what has been migrated at a field by field level. It gives a list of source fields from the legacy system against corresponding fields of the target system. Where there is no comparable source field it may just show a default value. The mapping may be included in this document or held in separate excel spreadsheets and referred to.
These contain control totals for each part of the migration. They detail simple things like the number of clients and policies and gives evidence of more complex things like the value of your accounts by risk on a year by year basis.
This document is aimed at the business user and there is no technical detail. It contains a section for each area of the migration including all details of transformations that were used, any data quality rules and details of any records that were excluded. It also contains a description of the logic used (i.e. business rules) to get the data from the old to the new system. It should be signed off by each team in the business prior to go-live. (i.e. Policy Administration, Stats, Claims etc.)
The above documents will provide a Comprehensive Audit Trail of the migration process and will give you peace of mind that your migration is complete, fully auditable and compliant.
To find out more about our range of insurance data migration services please follow this link.





We have experience in successfully migrating data to / from most of the major policy administration / underwriting system in the UK and many bespoke systems.
Managing Director, Paul Johnson
Insurance Data Solutions
Insurance Data Solutions
Registered Address:
Dalton House,
9 Dalton Square,
Lancaster,
LA1 1WD
Contact Information
